
First things first- I don’t think Bing is doing this intentionally- maybe they ARE aiming for a content play, however the issues I am highlighting today are probably a result of two things:
- Google crawling another search engine (which it shouldn’t)
- 302 hijacking is working again, even at an onsite 302 level
The other thing I would like to highlight is that this isn’t new. Bing hitting Googles SERPs has been going on for years. Rishi Lakhani is awesome.
The Discovery – Bing these SERPs
I often screw around with search result pages to stress test them for hundreds of queries. It’s one of the best ways to spot and learn more about how search engines treat different content and sites.
One of the queries I like to run is a “site:” search. And for some reason I ran “site:Bing.com” and the results were interesting to say the least.
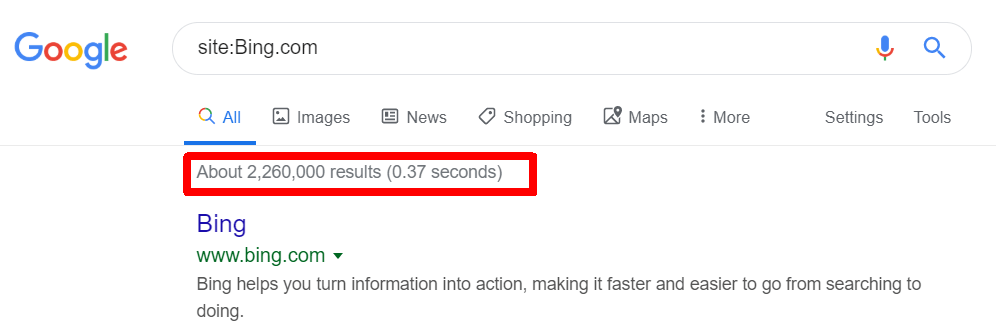
Decoding the results
So what are we seeing here? Well to start with there are a LOT of results from Bing in the Google SERPS – way more than you would expect. So I started going down the list manually.
Some of these are legitimate, but some not so much:
Site domains
Basically FULL site URLs and domains are in the index – appearing as if they are from Bing:
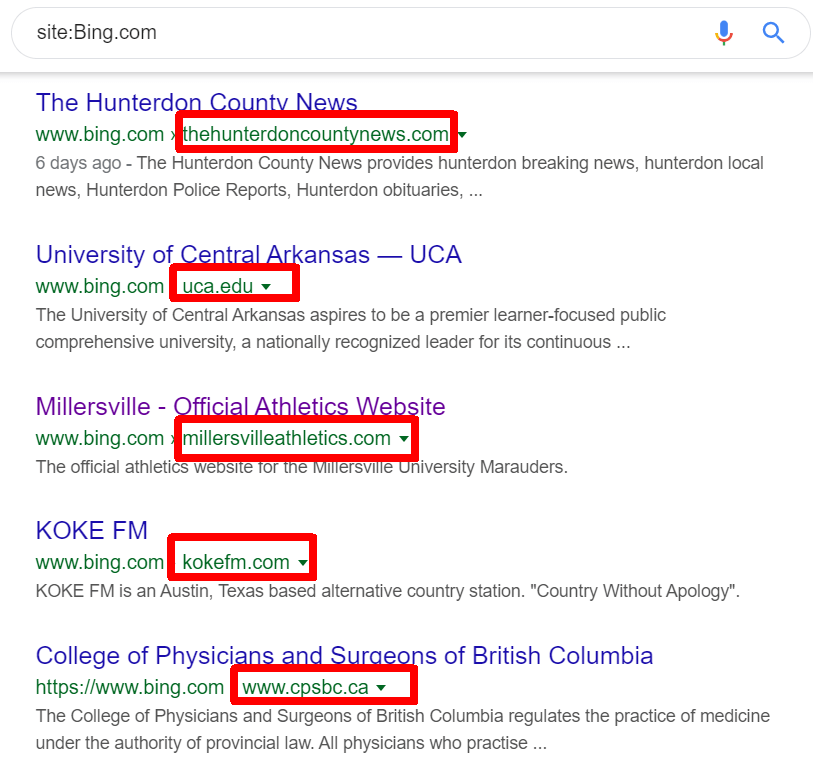
This is what the indexed domain URLs look like in google:
http://www.bing.com/cr?IG=C280B85FC9D24D39BAF610E31672E015&CID=1C57CDD4622C61572E08C781631D602A &rd=1&h=lFRXyg0M5pdx6N03d0ebgayAvD2Zc7q8OCmpnSGaTzc&v=1&r=http%3A%2F%2Fuca.edu%2F&p=DevEx,5092.1
This is what the Redirect Path Journey looks like:
First is the browser 307 from http to https:
http://www.bing.com/cr?IG=C280B85FC9D24D39BAF610E31672E015&CID=1C57CDD4622C61572E08C781631D602A&rd=1&h=lFRXyg0M5pdx6N03d0ebgayAv D2Zc7q8OCmpnSGaTzc&v=1&r=http%3A%2F%2Fuca.edu%2F&p=DevEx,5092.1
Leading to the https version:
https://www.bing.com/cr?IG=C280B85FC9D24D39BAF610E31672E015&CID=1C57CDD4622C61572E08C781631D602A&rd=1&h= lFRXyg0M5pdx6N03d0ebgayAv D2Zc7q8OCmpnSGaTzc&v=1&r=http%3A%2F%2Fuca.edu%2F&p=DevEx,5092.1
Which then redirects 302 to:
http://uca.edu/
Which then resolves (200 ) at the correct https verion:
https://uca.edu/
Isolating the “cr?” parameter, you can see the level of indexation:

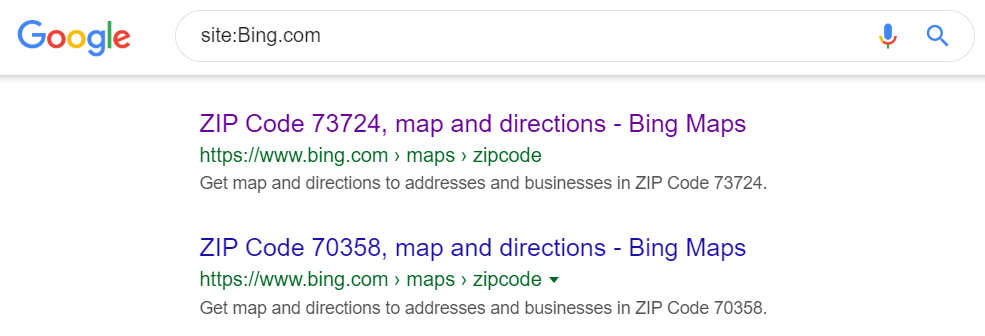
Map results
So a large portion of Bings map URLs are in the index:
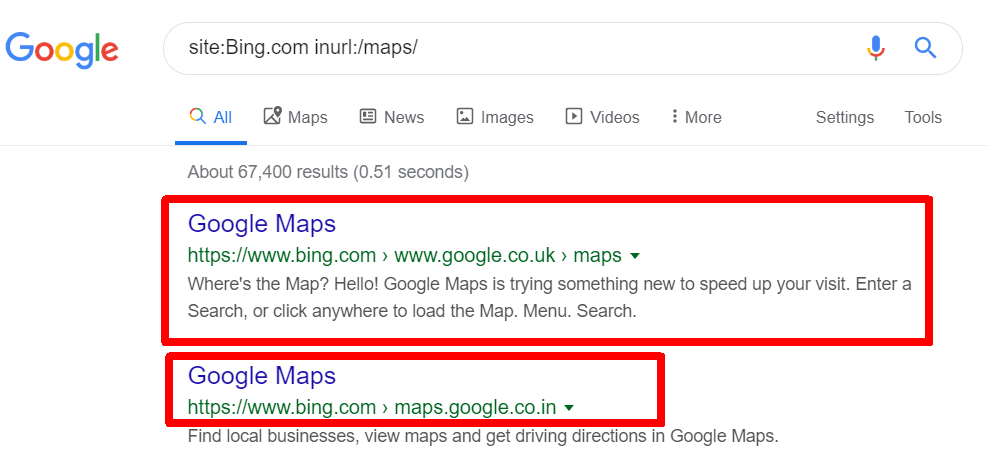
It gets more interesting – by running the query site:Bing.com inurl:/maps/ it appears Bings redirected urls for Googles OWN maps are in the index too:
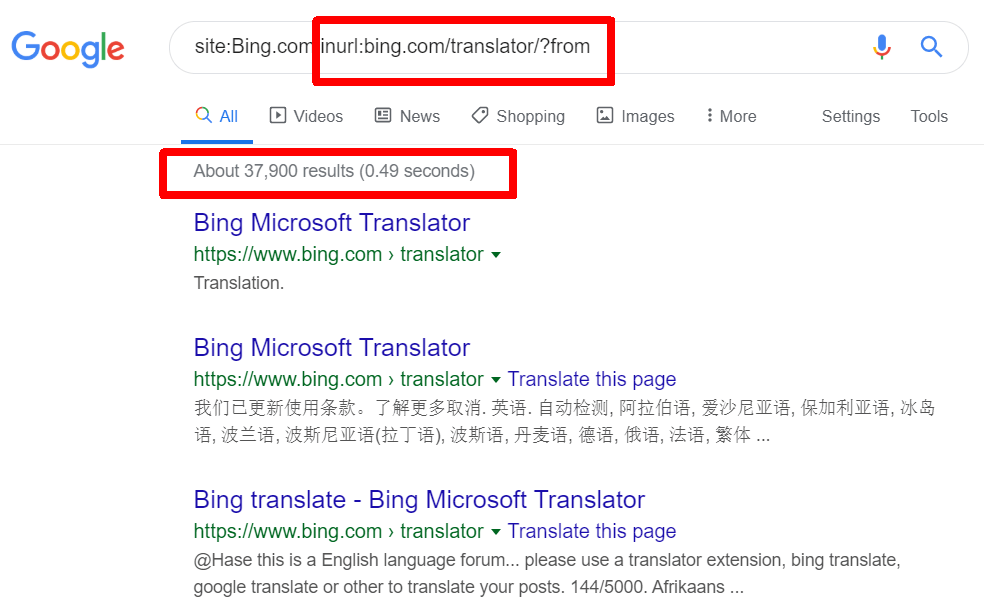
Translator results
Nothing super interesting there – apart from having that many pages indexed.
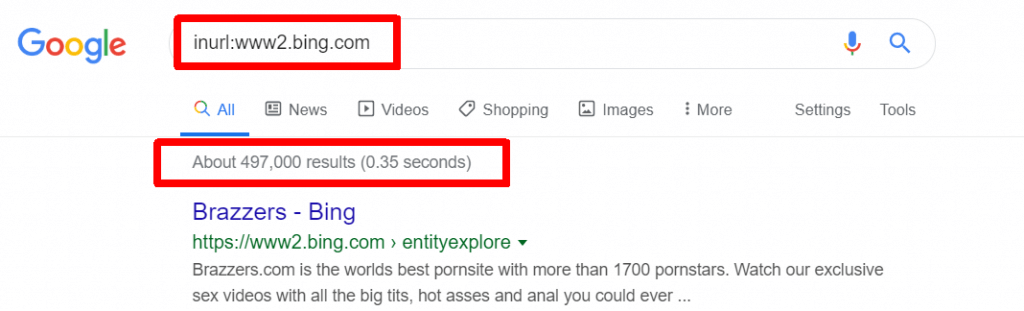
WWW2 sub domain
Bing had a feature it was using to serve up what it called its Entity Explore results. At some point they migrated them to the www2 sub-domain. Just under half a million results in the index:
This one is specifically interesting – but will go into some detail bit later in this post.
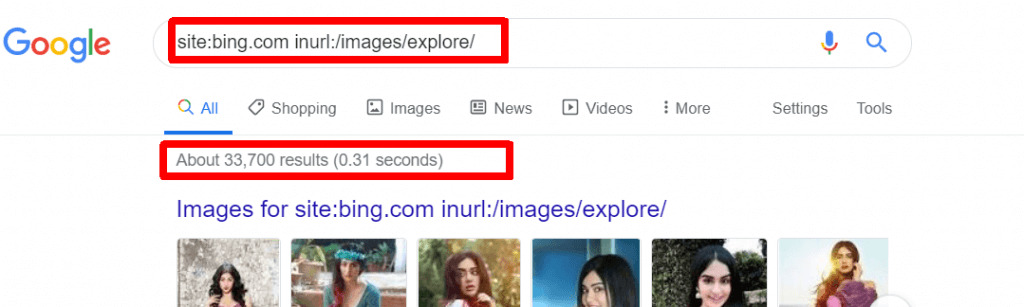
Image results
So a large portion of Bings image search results are in the index too. Not significant numbers (yet!), but enough. These are actually the ones that get very interesting. I will explain why in a bit.
Why do I care about Bing in Google?
Well to start with with Bings site authority is strong enough to force through results again significant volumes of incidental rankings. This means over time, unless fixed, these results will start ranking better.
In fact we are already seeing some domination for a range or queries and its going up. Having a history experimenting with high volume spamming of Google, I know for a fact that these type of results can drive serious hyper long tail traffic. Here is what SEMrush has to say about non-branded keywords and traffic Bing gets from google each month:
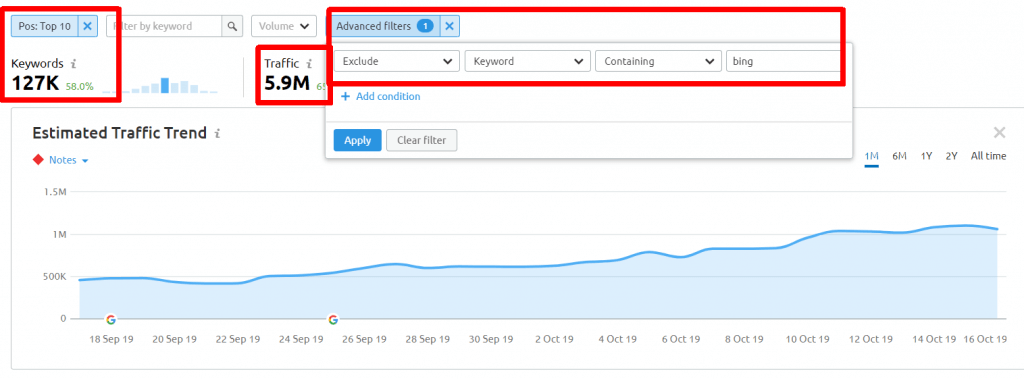
Earlier in the post I mentioned I will cover two type of results:
- Explore URLs
- Image Results
Without boring you any more, suffice to say both types of urls are 302 redirects.
This is the traffic the Explore Subdomain gets according to SEMrush in the US:
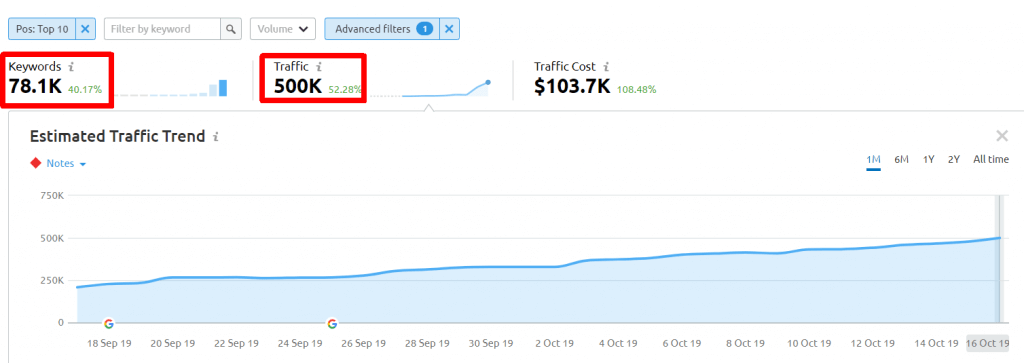
This is the traffic the Image results get according to SEMrush in the US:
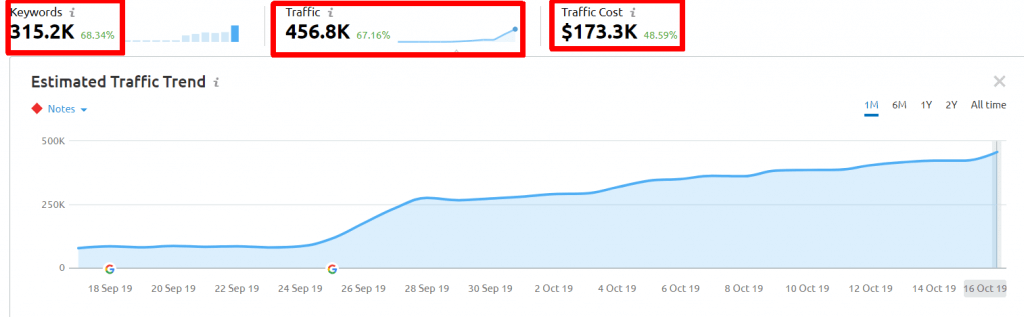
Should we look at some of the results?
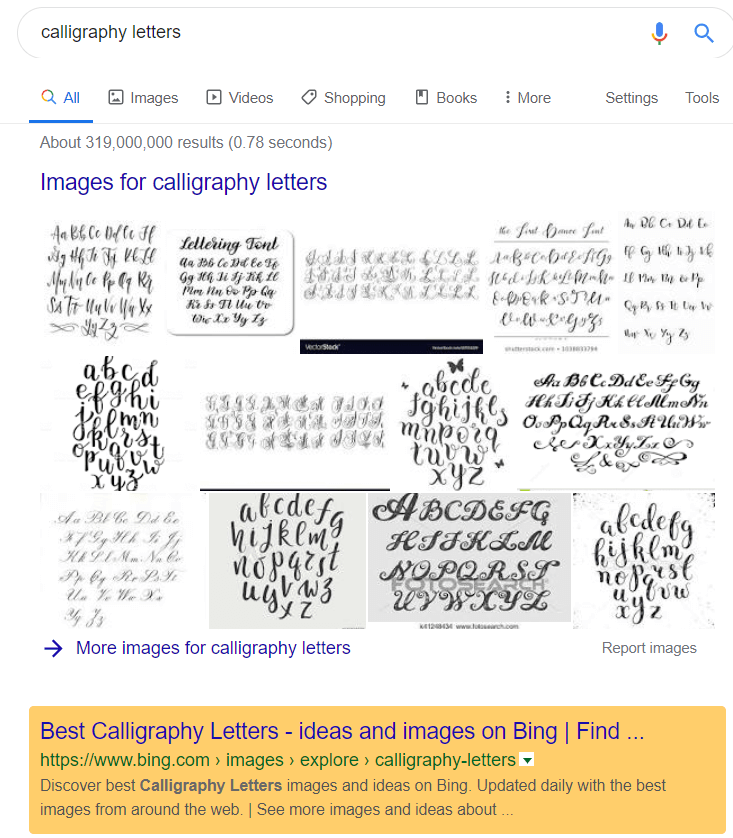
KW: “Calligraphy Letters” – Estimated Search Volume 27,000, Position #1:
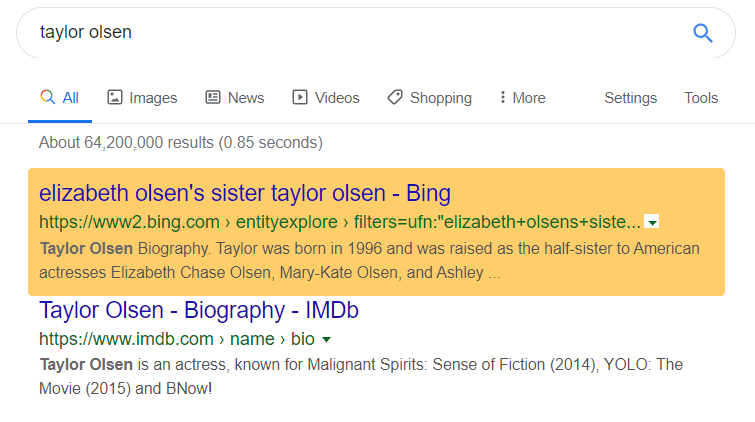
KW: “Taylor Olsen” – Estimated Search Volume 12,000, Position #1:
What are we learning?
There is still a lot to unpack here, I haven’t really dug deep enough, maybe some other time. For now, as I have said earlier in this post, it isn’t the first time we are seeing this – and if the SEMrush data is anything to go by, the traffic volume potential hasn’t even reached some of its historical peaks:
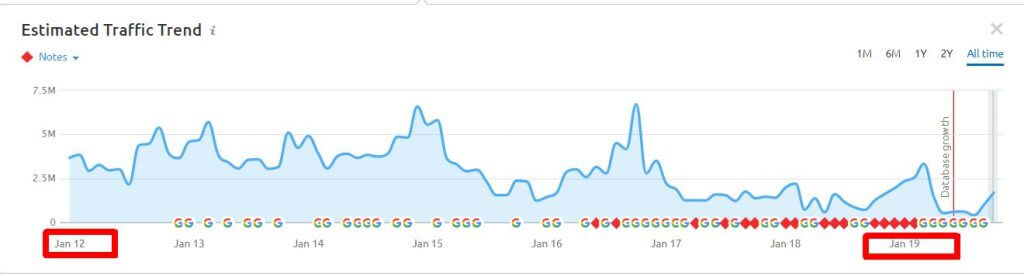
Ond-omain 302 redirect hijacks are working again. What’s a 302 hijack? Well it’s a way to get any url ranked without any real content on it. You can see my detailed guide on it here. An on-domain 302 redirect is simply a redirect to an content on your own site.
We are also learning that with a high enough domain authority and signals used to confuse the crawler and algorithm, its is fairly easy to spam Google with results that pretty much add no real value.
The other obvious problem is that the google algorithm keeps struggling with dealing with these type of techniques – 302 issues have been around as long as I can recall.
The question is – should Google be doing anything about these results? Driving a user from their own results into another search engines results is a bad user journey in my opinion. The other question is – should Bing really be allowing Google to crawl and index its search results? Its free traffic I guess – but both search engines must be spending an enormous crawl budget to crawl one another. Its insane.
In the meantime, if you’re looking for an SEO expert to boost your organic search rankings get in touch with us.